
Financial Sentiment Analysis with LLM
Building a High-Performance Batch Processing Server for Sentiment Analysis with Starlette and Hugging Face Transformers

Introduction
To process high volumes of sentiment data in real time, Intrinsic Research has developed the Batch Processing Server, a high-throughput, scalable application. Leveraging the asynchronous capabilities of Starlette and the powerful NLP models from Hugging Face, this server enables analysts to gain actionable insights quickly. This article will walk through the Batch Processing Server’s setup for local testing and deployment on Google Kubernetes Engine (GKE).
Project Overview
The Batch Processing Server is designed to handle high volumes of text data, detecting sentiments such as "positive," "neutral," and "negative." This capability is crucial for use cases in financial markets, real-time news sentiment analysis, and social media monitoring. Built with asynchronous request handling and batch processing, the server maximizes processing efficiency and scalability.
A core component of this server is its integration with the FinBERT model, a specialized large language model (LLM) from Hugging Face Transformers. FinBERT was developed specifically for financial sentiment analysis, a unique subset of natural language processing (NLP) that analyzes language patterns and vocabulary commonly found in financial texts. Unlike general-purpose language models, FinBERT is fine-tuned on financial news, earnings reports, and related texts, making it particularly skilled at understanding financial jargon and nuances.
Why FinBERT Qualifies as an LLM
FinBERT is a large language model (LLM) based on BERT (Bidirectional Encoder Representations from Transformers), an architecture developed by Google for language understanding. As an LLM, FinBERT possesses several defining characteristics:
Contextual Understanding: It uses the Transformer architecture to understand word relationships in context, which is essential for accurately interpreting financial sentiment in complex statements.
Pre-training on Extensive Financial Data: FinBERT was pre-trained on a vast dataset of general language, then fine-tuned on specific financial data. This dual training enables it to accurately assess nuanced sentiment in financial contexts.
Scalability for Large Data Volumes: FinBERT’s architecture and large-scale training allow it to perform efficiently even with high-throughput data, making it ideal for integration in real-time sentiment analysis applications like the Batch Processing Server.
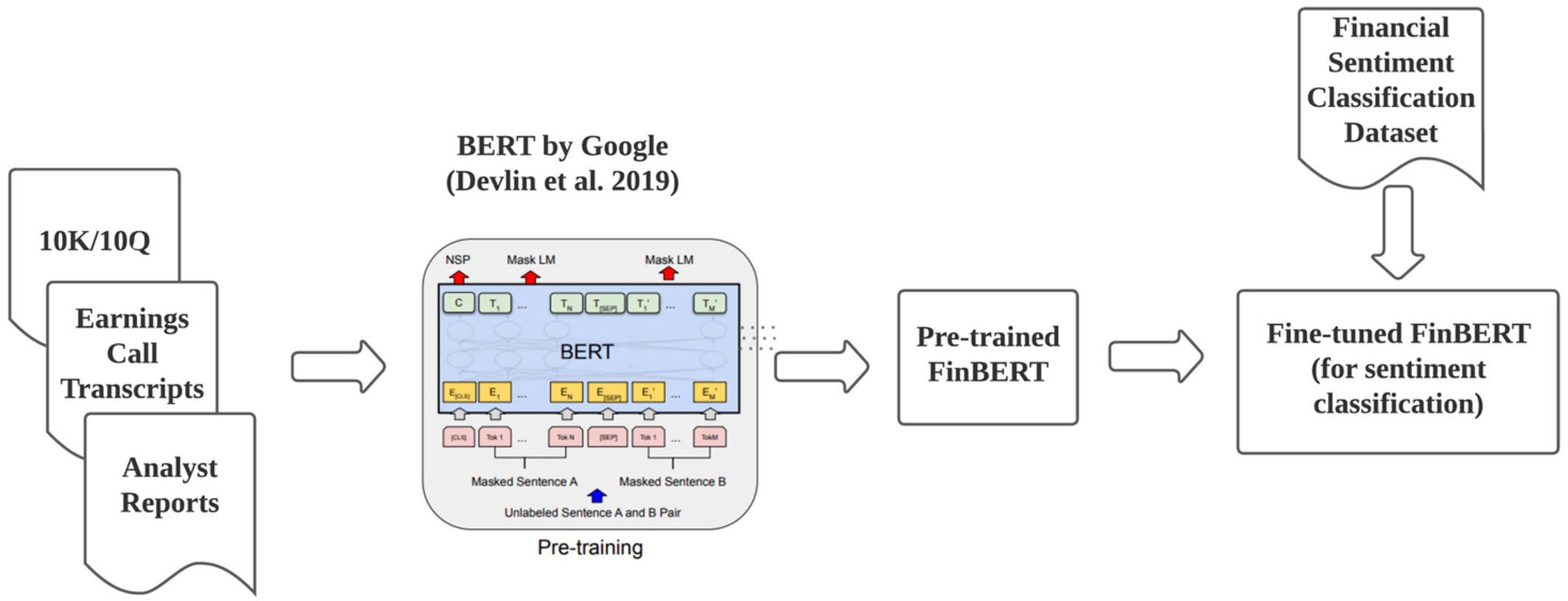
This combination of domain expertise and advanced language modeling allows FinBERT to serve as a robust tool for deriving meaningful insights from financial text data, delivering value in dynamic environments where sentiment can influence decision-making rapidly.
Key Features
ASGI Server with Starlette: The Batch Processing Server employs Starlette, an ASGI framework known for its high performance in handling asynchronous requests. This design enables the server to process multiple requests concurrently, making it ideal for high-traffic environments.
Asynchronous Batch Processing: A queue-based system efficiently manages batch data processing, optimizing for both memory usage and computational speed, even when handling large datasets.
Getting Started
To set up and run the Batch Processing Server locally, follow the steps below.
Step 1: Clone the Repository
Clone the repository from GitHub to get the latest version of the server:
git clone https://github.com/Ryan-Ray-Martin/sentiment-batch-processing.gitStep 2: Set Up a Python Virtual Environment
Create a virtual environment to isolate project dependencies:
python3 -m venv venv
source venv/bin/activate # On Windows use `venv\Scripts\activate`Step 3: Install Dependencies
Install the required packages:
pip install -r requirements.txtUsage
With the setup complete, you’re ready to start the server and process data.
Start the Server
Use Uvicorn, an ASGI server optimized for Starlette, to launch the Batch Processing Server:
uvicorn batch_server:app --host 0.0.0.0 --port 8000Send Batch Data for Sentiment Analysis
Once the server is running, you can send JSON data for sentiment analysis. Use a command-line tool like curl or an HTTP client to post data to the server.
Example Request:
curl -X POST -H "Content-Type: application/json" -d '[{"text": "Stocks rallied and the British pound gained."}, {"text": "The economy showed significant growth."}, {"text": "Investors are optimistic about the market."}]' http://localhost:8000/Example Response:
The server will return sentiment labels and scores, providing a clear view of sentiment trends.
[
{ "label": "positive", "score": 0.898361325263977 },
{ "label": "positive", "score": 0.948479950428009 },
{ "label": "positive", "score": 0.6735053658485413 }
]
Customization Options
Model Configuration
The server’s default model is ProsusAI/finbert, specifically tuned for financial text analysis. To experiment with other models, modify the configuration in batch_server.py.
Deployment on Google Kubernetes Engine (GKE)
Deploying the Batch Processing Server on Google Kubernetes Engine (GKE) is advantageous for its scalability, automated resource management, and integrated load balancing. This configuration allows the server to handle large volumes of sentiment analysis requests with low latency and high reliability. Here’s how to deploy it to GKE:
Why Choose GKE for Deployment?
GKE offers several benefits that make it an ideal platform for deploying large-scale batch processing applications:
Auto-scaling and Managed Resources: GKE scales your infrastructure to meet workload demands, automatically managing server resources.
Integrated Load Balancing: With
model_serve.yaml, GKE configures a load balancer to distribute requests across server instances, maintaining optimal performance.Comprehensive Monitoring and Health Checks: GKE continuously monitors the infrastructure, making it easy to identify and address any issues before they impact performance.
Seamless Integration with Google Cloud Services: GKE integrates well with Google Cloud’s data analytics tools, such as BigQuery and Pub/Sub, enabling complex data processing pipelines.
GKE Deployment Steps
Follow these steps to deploy the Batch Processing Server with load balancing on GKE:
Step 1: Create a GKE Cluster
Begin by creating a Kubernetes cluster to host your server:
gcloud container clusters create ml-model-cluster \
--zone us-central1-a \
--num-nodes 3 \
--machine-type e2-standard-4Step 2: Create a Kubernetes Deployment
Deploy the application on the newly created cluster:
kubectl apply -f deploy_model.yamlStep 3: Expose the Server Using a Load Balancer
To ensure efficient request handling, apply model_serve.yaml to configure a load balancer for the deployment:
kubectl apply -f model_serve.yamlThis setup allows traffic to be balanced across multiple instances, providing high availability and low response times even during peak traffic.
Step 4: Retrieve the External IP Address
Get the external IP of the load balancer to make the server publicly accessible:
kubectl get services ml-model-serviceWith the IP address from this command, you can now interact with the server from external applications.
Testing the Deployed Service
To confirm the deployment, send a test request to the load-balanced external IP address:
curl -X POST -H "Content-Type: application/json" -d '[{"text": "Stocks rallied and the British pound gained."}, {"text": "The economy showed significant growth."}, {"text": "Investors are optimistic about the market."}]' http://<EXTERNAL-IP>:80/Conclusion
Deploying the Batch Processing Server on GKE with load balancing ensures it can handle high demand, scale automatically, and provide reliable, low-latency responses. The setup leverages GKE's auto-scaling, monitoring, and load-balancing capabilities, which is critical for applications that need to handle fluctuating workloads efficiently. This configuration provides a reliable, production-ready environment for financial sentiment analysis, supporting analysts and researchers with real-time data insights.
References
Araci, D. T. (2019). FinBERT: Financial Sentiment Analysis with Pre-trained Language Models. [Master's thesis, University of Amsterdam]. arXiv. https://doi.org/10.48550/arXiv.1908.10063
Huang, A.H., Wang, H., & Yang, Y. (2023). FinBERT: A Large Language Model for Extracting Information from Financial Text. Contemporary Accounting Research, 40: 806-841. https://doi.org/10.1111/1911-3846.12832